
Data remains an intangible asset on most companies’ balance sheets—and its value is too often indeterminable and not fully tapped. Figures compiled by market researcher IDC estimate that only 32% of data available to enterprises is fully leveraged.
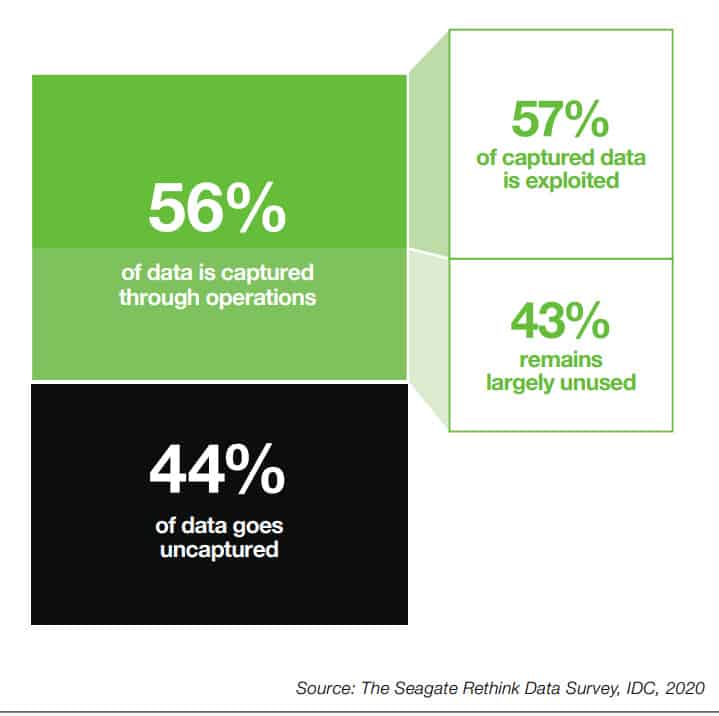
The research firm surveyed more than 1500 respondents worldwide and found that the remaining 68% is untapped and unused. Major barriers include ineffective data management, data growth and sprawl, and ensuring proper data security.
To extract the most value from the data, many companies are increasingly turning to constructing cloud-based data lakes or a unified data storage platform.
A data lake is a platform that centralizes all types of data storage. It provides elastic storage capacity and flexible I/O throughput, covering different data sources, and supporting multiple computing and analytics engines.
A data lake can be hundreds of petabytes (PB) in size – or even larger. Organizations are looking to create a unified view of all their corporate data – and to gain a working knowledge of the patterns emerging from this data set that leads them to take action to address real-life business challenges.
A big risk in any data lake project is that – if left unattended - it could turn into a data swamp, or a repository where unleveraged yet potentially useful data sits dormant on storage media. It risks becoming a massive, mostly idle swamp of “sunk” data that is completely inaccessible to end-users—a waste.
To keep data lakes from morphing into swamps—and keep them fresh, vibrant, and full of insights—CIOs, CTOs, and data architects should implement the following four points.
1. Have a clear vision of the business problem you're trying to solve
With a well-articulated objective in mind, it should be relatively straightforward to target the data you need to collect and the best machine learning techniques for gleaning insight from that data.
Most business outcomes can benefit from an investment in storage infrastructure. Organizations should then seek to quantify and measure the benefits of such an investment.
In advertising, a data lake analytics engine can be leveraged to run advertising campaigns accurately by reaching the correct groups of people through the right channels.
A data lake can be used to perform data collection, storage, and analytics across the full lifecycle of data management.
For the above to work effectively, it’s important that new data is constantly introduced into the data lake so optimal results can be extracted with the right software applications.
2. Capture and store all the information you can
Organizations need to be able to capture the right data, identify it, store it where it is needed, and provide it to decision makers in a usable way. Activating data—putting it to use—starts with data capture.
Given the overwhelming growth of data due to the proliferation of IoT applications and 5G deployments, enterprises cannot keep up and do not currently capture all available data.
But increasingly enterprises are learning to capture and save as much data as they can in order not to miss out on its complete value—the value that’s there today and the value that will come alive in the use cases of tomorrow. If the data is not stored, this value never materializes.
In the early days of data lakes, it was the power user who had the ability to dive in, swim in the lake and find the right data. Nowadays Structured Query Language (SQL) has made big inroads into the data lake and given ordinary users more access to the data.
3. Periodically evaluate the data
Data lakes need auditing and refreshing. Enterprises should review the datasets they’re managing in a cloud-based data lake – or they will find that the data lake becomes increasingly harder (muddier) to use.
Worse yet, the organization’s data scientists will find it more difficult – if not impossible – to find the patterns in the data that they’re searching for.
The use of cloud storage services, along with AI and automation software, is expected to have the most impact on making massive data lakes more manageable. It remains the magical solution for ploughing through the information.
For example, in fraud detection in a bank, AI-based systems being designed to learn what type of transactions are fraudulent, and then use neural networks to determine them based on frequency of transactions, transaction size and type of retailer.
4. Engage mass data operations
Mass data operations, or DataOps, is defined by IDC as the discipline of connecting data creators with data consumers. DataOps should be part of every successful data management strategy.
In addition to DataOps, a sound data management strategy includes data orchestration from endpoints to core, data architecture, and data security.
The goal of data management is to facilitate a holistic view of data and enable users to access and derive optimal value from it—both data in motion and at rest.
Conclusion
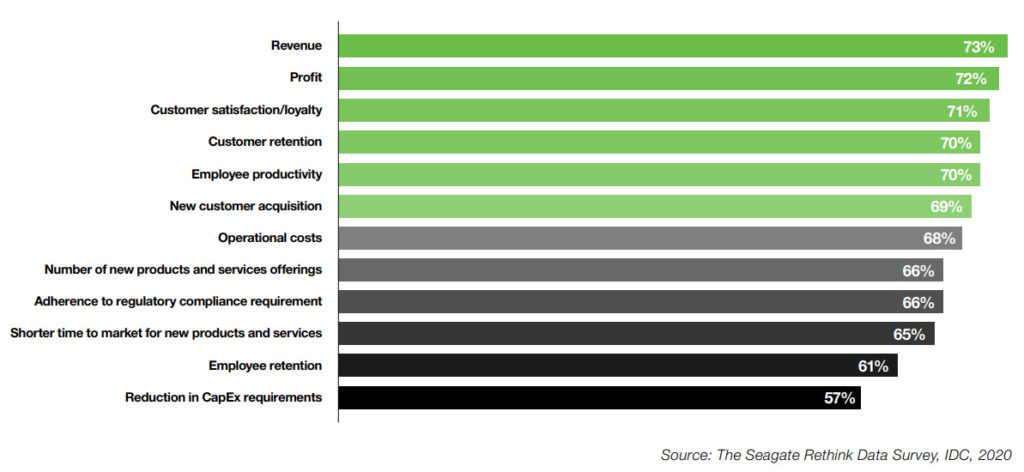
Businesses today are generating massive amounts of enterprise data, which is forecast to grow at an average annual rate of 42% annually from 2020 to 2022, according to IDC’s Rethink Data report.
Given the rapid pace of digitization-- accelerated in many cases by the pandemic -- many organizations are gathering and managing more data than ever before.
Cultivating vibrant and insightful data lakes will lay the groundwork for long-term success of enterprise data management strategies, in turn enabling the success of digital infrastructure and business initiatives.
Following the four steps above should ensure that your organization has access to vibrant lakes powering the scalable, secure, and compliant data-driven business models of the future.


