
Most organisations today understand the importance of infrastructure monitoring, given the need to ensure 100% site uptime and 24/7 business continuity. But with the widespread shift to remote work and the rise of digital transactions, IT and developer teams have been under greater pressure than ever before. Close to one in two (48%) of IT leaders in Asia Pacific reported that they had seen an increase in downtime since the pandemic began.
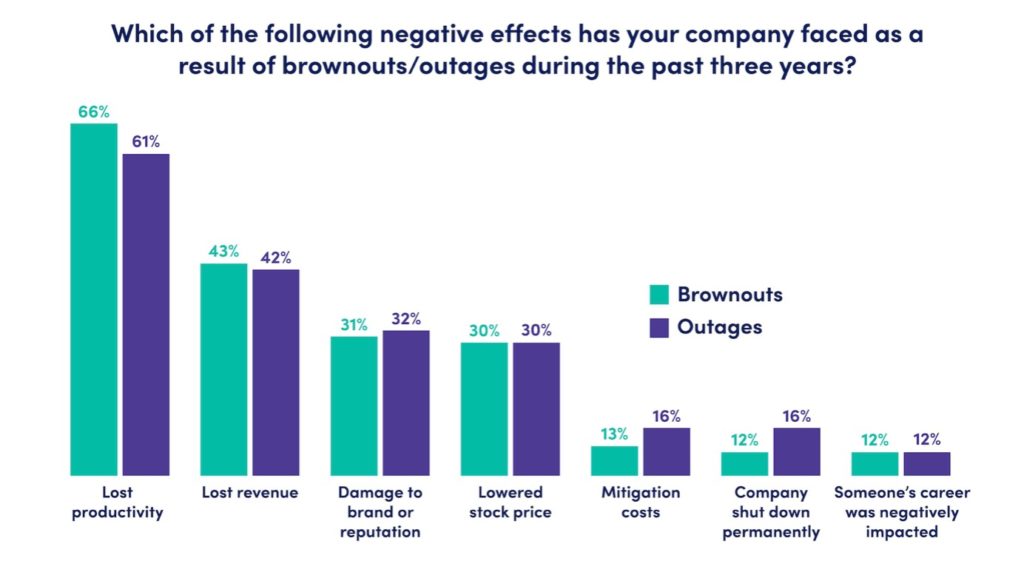
(Source: LogicMonitor “The Race to IT Observability” report)
From revenue losses to a reduction in productivity, or even damage to brand and reputation, the negative impact of downtime in today’s digital world is extensive, and often too severe to fully quantify. Organisations may already have infrastructure monitoring solutions in place, but are they using it to the fullest potential?
Here are some of the most common monitoring mistakes that IT teams are making and how to address them.
Mistake #1: Relying on individuals and human-driven processes
According to a Gartner report, 47% of IT organisations experience more than 50,000 alerts per month. While not all alerts are relevant or time-sensitive, the sheer volume of alerts will no doubt overwhelm IT professionals, leading to cases of employee burnout. Alerts may be ignored, responses slow, and incident management gradually gets worse.
It comes without saying that replacing the human configuration with automation tools powered by Artificial Intelligence (AI) will not only improve monitoring and prevent downtime but will also offload people’s time to focus on more important tasks.
In fact, AI, Cloud Computing and Automation are the top three areas that IT leaders are focusing on by 2025.
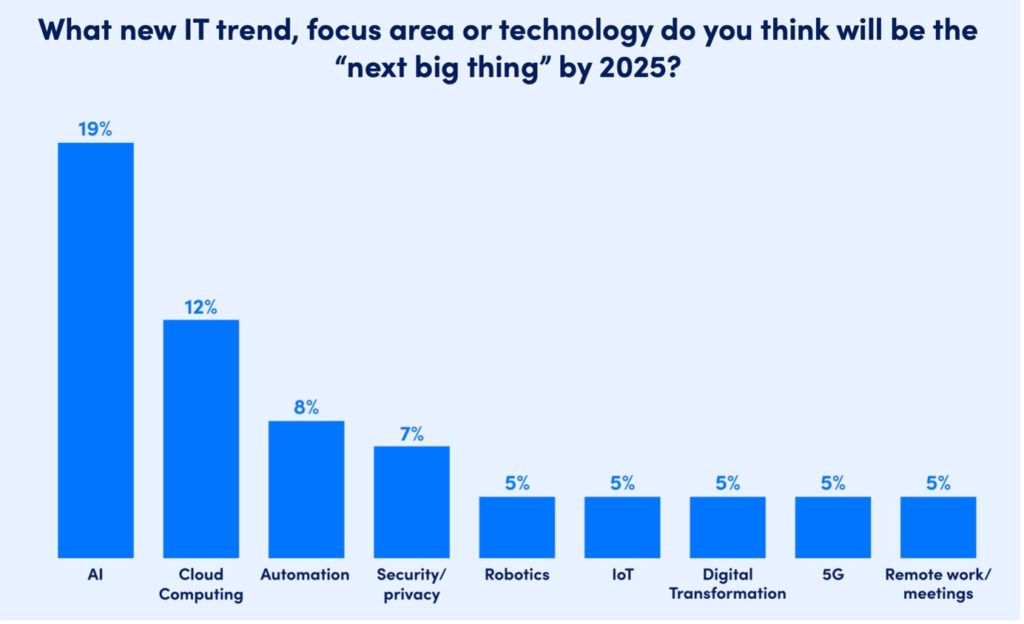
(Source: LogicMonitor “The Race to IT Observability” report)
At the very least, an effective monitoring tool should be able to continuously monitor devices for modifications, filter and classify discovered changes to avoid alert overload, and automatically add new machines or instances for monitoring.
Mistake #2: No recurrence - problem solved
Outages are inevitable, even when good monitoring practices are followed. While the top priority would be to solve the problem immediately when it happens, the troubleshooting process should not end there.
Monitoring solutions can identify the root cause of the problem and help IT teams put in processes and early warnings to ensure that history does not repeat itself.
For instance, an outage caused by an exceptionally high volume of traffic probably exhibited an increase in the number of customer support queries. IT teams can modify their monitoring solutions to watch for this increase and set an alert threshold to a point where the number of queries is rising above the average range. This would allow IT teams to be notified through advanced warnings the next time a similar situation occurs.
Early warning provides a window in which to avoid the outage. IT teams will have ample time to add another system to share the load or activate load-shedding mechanisms. Configuration of alerts in response to downtime allows teams to be proactive for future incidents.
Mistake #3: Monitoring System sprawl
One. That is the ideal number of monitoring systems the organisation should be adopting.
Many organisations still use different types of monitoring solutions for different uses, such as database monitoring, server monitoring and web monitoring.
And monitoring for IT teams becomes more overwhelming when multiple systems for Windows, Linux, MySQL and more are in play. With so many siloed inputs, IT teams can be distracted from seeing and filtering out the most important information.
In the case of monitoring systems, less is better. Consider adopting a single, vendor-agnostic monitoring software that can perform all the necessary tasks, providing a single source of information within one centralised location. IT teams need one place to monitor as many different technologies as possible to ensure that they are ‘singing from the same hymn sheet’.
Mistake #4: Not monitoring your monitoring system
False security is worse than having no monitoring system at all. A common mistake by organisations is that once they have invested significant capital in a monitoring system, they become complacent and presume it can be left alone without regular monitoring. It might seem counterproductive, but monitoring systems need to be monitored as well.
The fact is that monitoring solutions are not fool-proof – they can still fail. A monitoring system encompasses the complete system, including the ability to send alerts. When a network connection goes down, even if the monitoring system does its job and detects the outage, this incident will only be apparent to IT teams that are watching the console.
The onus falls on the IT teams to execute regular manual health checks on the monitoring system to ensure that it runs like clockwork. Organisations can minimise their risks of undetected outages by configuring a check of their monitoring system from a location outside the reach of the monitoring system.
Alternatively, they can select a cloud-based monitoring solution that is not only hosted in a separate location but also grants the ability to monitor the health of their own monitoring solution from multiple locations.
While enterprises will never be able to eliminate every monitoring system from their operations completely, they can begin to radically reduce IT tool glut that for years has hampered IT operations.
By subsuming basic infrastructure management functionality into a vendor-agnostic analytics platform, companies can begin shedding significant cost and complexity from today's network operations while adding much-needed visibility into critical network blind spots that litter today's corporate access networks.

