
There is a growing desire among organisations to become more data-driven. The view is that data should be the foundation of business decisions as opposed to gutfeel. Gartner says "Progressive organisations are infusing data and analytics into business strategy and digital transformation by creating a vision of a data-driven enterprise, quantifying and communicating business outcomes, and fostering data-fuelled business changes."
One technology that has become foundational to this drive to become data-driven is advanced analytics – the use of data science and machine learning technologies to support predictive and prescriptive models.
But while 90% of companies advanced analytics' value, McKinsey claims that the majority of companies have been unable to unlock this value due to the lack of capabilities and repeatable processes needed to roll out new algorithms and analytics models.
Source: McKinsey
McKinsey believes that the remedy lies with DataOps. IBM defines DataOps as the orchestration of people, processes, and technology to deliver trusted, high-quality data to data citizens fast.
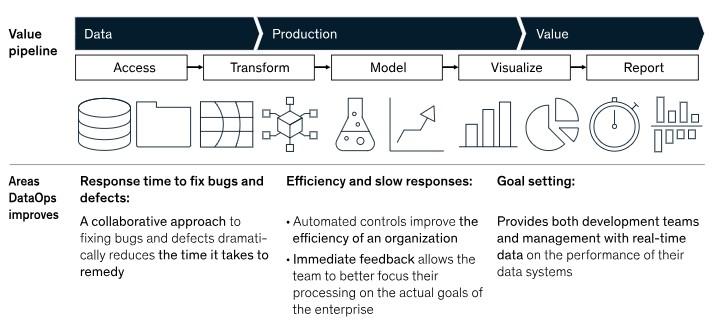
Kelvin Looi, VP of data & AI technology sales for IBM APAC, explains that the practice is focused on enabling collaboration across an organisation to drive agility, speed, and new data initiatives at scale.
He goes on to add that using the power of automation, DataOps is designed to solve challenges associated with inefficiencies in accessing, preparing, integrating and making data available.
Hitachi Vantara's enterprise solutions director for ASEAN, Lawrence Yeo, says DataOps provides a united view and understanding of disparate types of data that reside in silos and repositories across an enterprise.
"DataOps allows businesses to modernise their data environment with intelligent data flows so that they can maximise data as an enterprise asset by turning it into business value to gain a competitive edge even as they scale," he continues.
DataOps in the Data Observability Paradigm
Looi notes that DataOps takes care of the speed and agility of the end-to-end Data Pipeline processes from collection to delivery, Data Observability provides the ability to fully understand the health of the data and visibility for the data activities of an organisation.
"It detects, provides root-cause analysis and resolves data quality incidents in real-time. Data observability eliminates data downtime and reduces the business impact of bad data quality," he continued.
Yeo points out that Data Observability is an emerging discipline that aims to provide organisations with a comprehensive understanding of the health and performance of the data within its systems.
"It makes use of automated monitoring, machine learning, root cause analysis, data lineage, and data health insights to proactively identify, address, and avoid data abnormalities," he adds.

Data observability fits in with DataOps as a monitoring foundation and in providing visibility into complex data environments and assisting with data management."
Lawrence Yeo
The difference between DevOps and DataOps
Looi says DataOps brings a similar level of discipline to data availability as DevOps does to software development.
Yeo, for his part, says DataOps helps to make data more trustworthy and useful by breaking down silos between data producers and consumers. "DevOps, on the other hand, focuses on software development and coding, and on bringing development and operations teams together to make software development and delivery more effective," he elaborates.
Daniel Hein, Informatica’s chief architect for Asia Pacific & Japan, chimes in saying DevOps rests upon three fundamental principles: Continuous Integration, Continuous Delivery, and Continuous Deployment.

"We can broaden the application of these principles beyond the realm of application software to encompass data pipelines and data-driven applications. While DevOps deals with the delivery of software products, DataOps automates data orchestration by delivering data across an organisation."
Daniel Hein
DataOps vs Data Engineering
In the "Fundamentals of Data Engineering" by Joe Reis and Matt Housley, the authors labelled Data Engineering as one of the hottest fields in data and technology saying it builds the foundation for data science and analytics in production
IBM's Looi, Data Engineering involves tasks such as data ingestion, data transformation, data modelling, and data integration to ensure the availability of high-quality data for various business purposes.
Hein notes that Data Engineering focuses on the development, construction, and management of systems and infrastructure to facilitate the processing, storage, and analysis of large volumes of data. "It involves designing and implementing data pipelines, data integration processes, and data lakes and data warehouses to ensure that data is collected, organised, and made accessible for various analytical purposes," he continued.
In linking DataOps and Data Engineering, Yeo says: "What unites both disciplines is the creation of a system that allows for the effective extraction of data to produce value that will be advantageous to the business."
DataOps best practices
Mining the value of DataOps is no cakewalk. The top challenges include a lack of visibility across the data environment, lack of proactive alerts, expensive runaway jobs and pipelines, lack of experts and no visibility into cost and usage, according to the DataOps Unleashed Survey by Unravel.

"The purpose of DataOps is to create a benchmark that can be used to evaluate the impact of the new DataOps initiative. Once that is done, we need to identify the gaps to identify inefficiencies, error-prone jobs or manual workarounds that prevent the free flow of data from source to consumption. It is important to understand where we are wasting time, effort and money in these processes."
Kelvin Looi
Asked for one best practice, Yeo suggests beginning with a clear understanding of where they stand and what they want to achieve. "This involves knowing what data assets they have, the quality of that data, and how it flows throughout the organisation. They need to understand how they want to use that data, and what data governance exists," he added.
Hein suggests embracing DevOps principles within their data practices. By so doing, "Organisations can enhance the quality, reliability, and timeliness of their data assets, driving better decision-making and enabling data-driven innovation," he concluded.
The starting point for implementing DataOps
For Looi, the starting of a DataOps journey starts with the formation of a team responsible for designing and implementing the DataOps strategy. He believes the team should include stakeholders from different departments, such as IT, analytics, and business.
He also stressed that any success of DataOps will have its roots around data governance. "A solid data governance foundation makes it easier to discover and use the data. Well-executed data governance also ensures the data used has proper consent in compliance with the increasing privacy data protection acts in many countries," Looi elaborated.
Yeo suggested that organisations should look to a platform that delivers automated, AI-driven DataOps capabilities. "Such a platform would provide advanced analytics and create an integrated data fabric that is supported by a data catalogue for data quality improvements and governance," he opined.
In addition to automation, AI, metadata management, and data democratisation, Hein reminded us that people play a central role in a DataOps implementation. "There are many stakeholders, such as LOB business analysts, data scientists, data engineers, data stewards, data governance councils, InfoSec analysts, administrators, and more. System Thinking is crucial to enabling all these people to work together effectively," he posited.


