
Analysts like IDC and Gartner agree that cloud adoption in Asia continues to accelerate in 2021, thanks in part to the disruption to work caused by COVID-19 in 2021. Also, a big thank you to digital transformation – another beneficiary of the pandemic.
The initial challenge for many organisations was figuring out which cloud approach works best for their business. Those involved in the operational aspect of ensuring applications are running also have to contend with data management and data protection.
Workloads determined the IT infrastructure strategy
Anthony Spiteri, senior global technologist, product strategy at Veeam, acknowledged the accelerated cloud adoption in Asia in 2020. He attributes this acceleration to the need for employees to continue working remotely for much of the year.
“People working from home needed to be able to access data and work more efficiently. IT had to handle this shift and figure out where best to host these applications,” said Spiteri.
He acknowledged that despite the massive work from home, there was no equivalent exodus to the cloud for business-critical applications and data*. He observed that organisations quickly recognised that the public cloud was not the panacea it was thought to be. Instead, workloads dictated the approach that organisations would take.
Editor's pick: PodChats for FutureCIO: Enterprise computing trends in APAC in 2021
“This led to the adoption of multi-cloud, hybrid cloud as the strategy moving forward,” said Spiteri.
Appropriate data production strategy
For Spiteri, a data protection strategy should begin with user education, including awareness of the increased sophistication of malicious intent that followed the massive remote work in 2020.
“Secondly, understanding where your data is. Data displacement is occurring in a greater number of organisations that leverage different platforms to create data-critical workloads. Once it sits in a repository somewhere, the next step is making sure that the data is protected with some sort of immutability against malicious attack,” he commented.
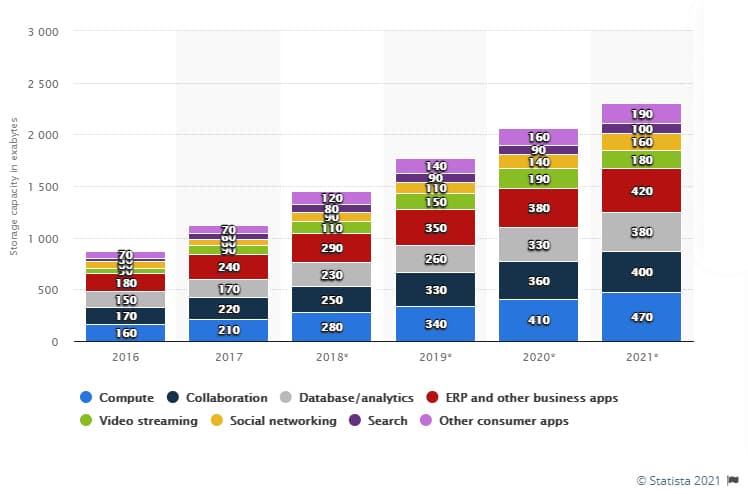
Per IDC’s Global Data Sphere, the world created, captured, copied and consumed 59 zettabytes (ZB) of data in 2020. IDC predicts that over 60% of G2000 organisations will be digitally dependent by 2021, and almost 80% in some industries by 2023 – leading to a massive increase in the data flow across and between organisations within industry ecosystems.
How much of that data is used after it is stored is up for debate. According to Spiteri, data that goes into the repository from a backup software sits there and effectively does nothing until it's needed.
“It's kind of like dead weight, burning through the walls of organisations,” he calls it.
He opined the idea of activating data – making it useful even though it is sitting in a backup repository. And moving forward, how to recover that data efficiently and quickly.
Artificial intelligence in data management
Gartner predicts that by end of 2024, 75% of organisations will shift from piloting to operationalising artificial intelligence (AI), driving a 5-times increase in streaming data and analytics infrastructures.
Spiteri acknowledged the rising awareness around automation and orchestration over the last five years.
“People understand that they need to be able to create repetitive tasks that create efficiencies within their business. The ability to leverage APIs, PowerShell and code through infrastructure as code to manage and control data protection platforms is critical,” he commented.
He feels however that AI and ML are still far away as a realistic everyday instance for organisations. He concedes the buzz is significant and a clear direction towards more accessible AI and machine learning platforms with then public clouds.
“But I think one area where that can be advantageous is if you look at data reuse, activating that data that's just sitting there otherwise stagnant. When you can bring up a repository from the backup source mounted somewhere and do some sort of machine learning or AI across that data – that is powerful for organisations moving forward,” he added.
Data protection in 2021
Spiteri expects 2021 to be about understanding that data is being created in larger volumes and different areas. He says it is about digital data displacement and how to secure and protect that data regardless of whether it is on the public cloud, on-premise for the long-term.
Spiteri sees 2021 as a year of consolidation.
“After last year, a lot of organisations now have the tool to deal with where data is being created and at the volume, it's being created as well,” he added. “You need to understand where data is being created, but then from a mobility perspective, how you protect it when it does move, if it moves, and then from that point of view, how do you then keep it for a long time? From our perspective, how you activate your data, make the data work for you, leverage automation, leverage orchestration tasks in the platform to be able to offer that to our customers.”
Click on the podchat player to listen to Spiteri elaborate on how some of the mundane yet critical aspects in the cloudification of business.
- We all know cloud adoption has increased in 2020 – but what has really changed in the cloud landscape?
- How prevalent/evident is multi-cloud within current IT environments today? How common is it to see workloads moving dynamically between clouds?
- With cloud-first being an accepted IT strategy, what does that it mean for data management and data protection?
- What are the key steps in the strategy to better protect data in 2021?
- What is next in the quest for automated data management across clouds?
- What do you predict for 2021 in the cloud data management space?


